
In today’s blog post, we will discuss stages keyword in .gitlab-ci.yml used to group multiple GitLab Ci/CD jobs. Specifically, we will learn what are stages?, How to define a stage in .gitlab-ci.yml with example, How jobs behave inside a stage, Tips and best practices while using stages, and will also cover most frequently asked questions regarding stages. So without any further delay, let us get started.
What are Stages in GitLab CI/CD?
In GitLab CI/CD, a stage is a logical grouping of jobs. All jobs within the same stage run in parallel (concurrently), provided there are available GitLab Runners. While jobs within a stage run in parallel, stages themselves run sequentially. This means that all jobs in a given stage must complete successfully before the next stage begins. If any job within a stage fails, the entire pipeline typically stops, and subsequent stages are not executed. This “fail-fast” behavior is a core principle of CI/CD, helping you identify issues early.
Think of stages as the major phases of your software development process. Common stages often include:
- Build: Compiling code, packaging applications, building Docker images.
- Test: Running unit tests, integration tests, end-to-end tests, linting.
- Review/Staging: Deploying to a review app or a staging environment for manual testing or stakeholder review.
- Deploy: Deploying to production.
Defining Stages in .gitlab-ci.yml
You define your pipeline’s stages using the stages keyword at the top level of your .gitlab-ci.yml file. The order in which you list the stages here is the order in which they will execute.
stages:
- build
- test
- review
- deployIf you don’t explicitly define stages, GitLab CI/CD will use a default set of stages: build, test, deploy.
How Stages Control Job Execution
Let us understand with an example:
stages:
- build
- test
- deploy
# Build Stage Jobs
compile_code:
stage: build
script:
- echo "Compiling application..."
- ./gradlew build
build_docker_image:
stage: build
script:
- echo "Building Docker image..."
- docker build -t my-app:latest .
# Test Stage Jobs
unit_tests:
stage: test
script:
- echo "Running unit tests..."
- ./gradlew test
integration_tests:
stage: test
script:
- echo "Running integration tests..."
- ./gradlew integrationTest
# Deploy Stage Jobs
deploy_staging:
stage: deploy
script:
- echo "Deploying to staging environment..."
- deploy_script --env=staging
only:
- develop
deploy_production:
stage: deploy
script:
- echo "Deploying to production environment..."
- deploy_script --env=production
only:
- mainIn this pipeline:
buildstage:compile_codeandbuild_docker_imagejobs will run in parallel. Both must succeed.teststage: Once allbuildjobs are successful,unit_testsandintegration_testsjobs will run in parallel. Both must succeed.deploystage: After alltestjobs are successful, eitherdeploy_staging(if ondevelopbranch) ordeploy_production(if onmainbranch) will execute.
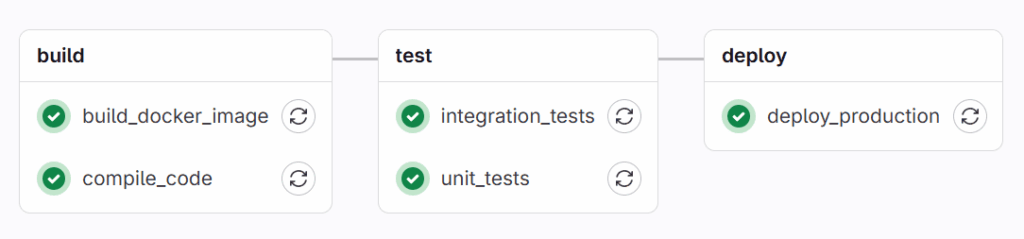
Important Behaviors of Stages:
- Parallel Execution within a Stage: This is key for speed. If you have multiple independent tasks that can run at the same time (like different types of tests), put them in the same stage.
- Sequential Execution Between Stages: Ensures that dependencies are met. You would not want to run tests on code that has not successfully compiled or deploy an application that failed its tests.
- Fail-Fast Mechanism: If any job within a stage fails, the entire pipeline stops, and subsequent stages are skipped. This prevents wasted resources and provides immediate feedback on issues. You can override this behavior for individual jobs using
allow_failure: true. - Skipping Stages: Stages can be implicitly skipped if all jobs within them are configured to be skipped (e.g., using
only/exceptorruleskeywords that prevent them from running on a specific commit).
Best Practices for Defining Stages
- Logical Grouping: Group jobs that perform similar functions or have strong dependencies on each other within the same stage.
- Keep Stages Focused: Each stage should ideally represent a distinct phase in your CI/CD process. Avoid creating “mega-stages” that try to do too much.
- Optimize for Parallelism: Whenever possible, design your jobs to run independently so they can be placed in the same stage and execute concurrently, reducing overall pipeline time.
- Balance Granularity: Do not create too many stages, as it can make your pipeline view cluttered and potentially slow down execution due to the overhead of starting new stages. Conversely, do not put too many disparate tasks into a single stage if they do not truly belong together or if a failure in one should not block others.
- Clear Naming Convention: Use descriptive names for your stages (e.g.,
build,test,security_scan,deploy_staging,deploy_production). - Consider Dependencies (
needs): While stages enforce sequential execution, for more complex dependencies where a job in a later stage needs to run immediately after a specific job in an earlier stage (without waiting for all jobs in the previous stage to finish), or if jobs in different stages are independent, explore theneedskeyword for creating a Directed Acyclic Graph (DAG) pipeline. This allows you to override the strict stage-based sequential execution. - Handle Failures Gracefully: Understand the fail-fast behavior. For non-critical jobs (e.g., generating documentation that is not essential for deployment), consider using
allow_failure: trueto prevent them from halting the entire pipeline.
FAQs – Stages
What is the stages keyword in GitLab CI/CD?
The stages keyword in GitLab CI/CD defines the order in which jobs are executed in the pipeline. Jobs are grouped into stages, and all jobs in one stage must complete before moving to the next. This helps structure your CI/CD process logically into phases like build, test, and deploy.
How do I define stages in .gitlab-ci.yml?
You define stages using a top-level stages keyword followed by a list of stage names:
stages:
- build
- test
- deployEach job must then reference one of these stages using the stage keyword:
compile:
stage: build
script:
- make
unit-tests:
stage: test
script:
- npm test
release:
stage: deploy
script:
- ./deploy.shJobs without an explicitly defined stage are assigned to the test stage by default.
What is the default stage order in GitLab CI/CD?
If you do not define a stages: list, GitLab uses a default order:
stages:
- build
- test
- deployHowever, it is good practice to explicitly define stages to avoid confusion and gain full control over pipeline flow.
Can I run jobs in parallel using stages?
Yes. Jobs in the same stage run in parallel, as long as runners are available. Only when all jobs in a stage complete successfully does GitLab move on to the next stage.
Example:
stages:
- test
job1:
stage: test
script:
- echo "Job 1"
job2:
stage: test
script:
- echo "Job 2"Both job1 and job2 run simultaneously.
What happens if a job in a stage fails?
If any job fails in a stage, GitLab stops the pipeline and does not proceed to the next stage. This ensures that only successful builds or tests lead to deployment.
You can make jobs non-blocking using allow_failure: true:
test-job:
stage: test
script: exit 1
allow_failure: trueCan I create custom stage names?
Yes. You can define any custom stage names relevant to your workflow:
stages:
- lint
- security_scan
- performance
- notifyThen assign jobs to these stages accordingly. The names are case-sensitive and should be consistent across jobs.
Is the stages keyword required in .gitlab-ci.yml?
No, it is not strictly required. If you omit it, GitLab still runs the pipeline using implicit stages, assigning jobs to the default stage test. However, omitting stages limits flexibility and can lead to unclear pipelines.
How can I visualize the order of stages in a pipeline?
After pushing your .gitlab-ci.yml to GitLab, go to your project’s CI/CD → Pipelines → View Pipeline to see a visual flow of stages and their respective jobs. This graphical representation helps you understand dependencies and parallelism.
Can I skip a stage based on conditions?
Yes. You can use rules, only, or except to control whether a job (and thus the stage it belongs to) runs:
deploy:
stage: deploy
script: ./deploy.sh
rules:
- if: '$CI_COMMIT_BRANCH == "main"'If no jobs in a stage match the condition, the stage is skipped.
How do I handle dynamic stages based on merge requests or branches?
Use the rules keyword to define jobs that should run in certain contexts:
integration-tests:
stage: test
script: ./run_integration.sh
rules:
- if: '$CI_MERGE_REQUEST_ID'This allows you to include or exclude stages dynamically based on GitLab’s predefined environment variables.
Can I run a manual job in a specific stage?
Yes. Use when: manual to create jobs that must be manually triggered from the GitLab UI:
deploy-to-prod:
stage: deploy
script: ./deploy_prod.sh
when: manualThis is often used for sensitive stages like production deployments.
What is the difference between stage and stages?
stages: A top-level keyword that defines the sequence of all stages in the pipeline.stage: A job-level keyword that assigns the job to one of the stages listed instages.
They work together to control the order and grouping of job execution.
Author

Experienced Cloud & DevOps Engineer with hands-on experience in AWS, GCP, Terraform, Ansible, ELK, Docker, Git, GitLab, Python, PowerShell, Shell, and theoretical knowledge on Azure, Kubernetes & Jenkins. In my free time, I write blogs on ckdbtech.com